DAY-1
인공지능 머신러닝 딥러닝 개요
오늘부터는 인공지능 활용에 대한 내용을 배운답니다!
전 사실 이날만을 기다렸답니다~

진짜진짜 궁금하고 배워보고 싶었던 내용이거든요.
그럼 오늘고 뽜샤!
인공지능(AI), 머신러닝, 딥러닝(Deep Learning) 소개
🧠
■ 일반적인 프로그래밍 vs 머신러닝
- 일반 프로그래밍: 사람이 명확한 규칙을 정해주고 컴퓨터가 그 규칙을 실행
- 머신러닝: 사람이 **데이터와 정답(label)**만 주면 컴퓨터가 규칙을 스스로 학습함
■ 머신러닝(Machine Learning)
- 사람이 데이터를 주고, 기계는 스스로 패턴이나 규칙을 찾아내는 방식
- 데이터에 기반하여 모델을 훈련시키고 예측 가능하게 함
■ 딥러닝(Deep Learning)
- 머신러닝의 하위 개념으로, 인공신경망(Neural Network) 구조를 통해 학습
- 데이터에서 복잡한 관계를 자동으로 학습하며, 레이어가 깊음
- 이미지 인식, 음성 인식, 자연어 처리 등에서 매우 강력한 성능을 보임
■ 관계 요약
인공지능(AI)
└── 머신러닝(ML)
└── 딥러닝(DL)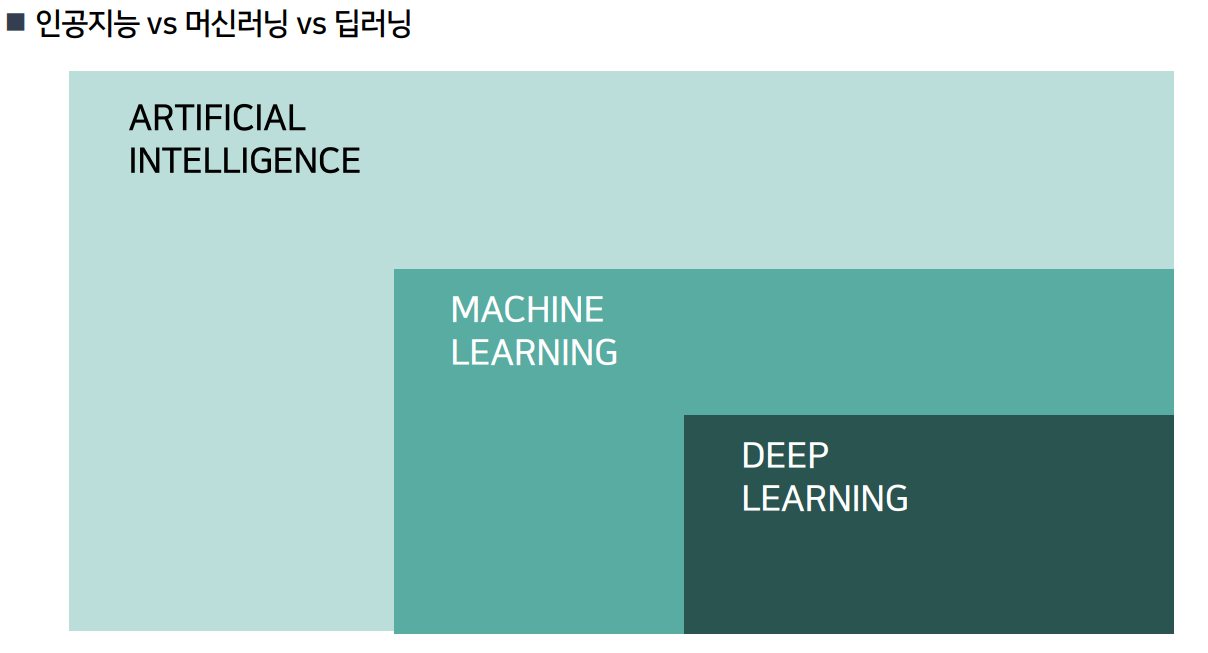
■ 머신러닝의 주요 유형
| 유형 | 설명 | 예시 |
| 분류 | 데이터를 범주로 구분 | 스팸메일 분류, 질병 진단 |
| 회귀 | 숫자값을 예측 | 집값, 매출 예측 |
| 군집화 | 유사한 데이터를 그룹화 | 고객 세그먼트 |
| 연관 규칙 | 항목 간의 관련성 찾기 | 장바구니 분석 |
머신러닝 프로세스
🔁

1️⃣ 문제 정의
- 해결하고자 하는 문제를 명확히 정의
- 예시:
- 당뇨병 여부 판단 → 이진 분류
- 다음 분기 매출 예측 → 회귀
- 문자 스미싱 여부 판단 → 이진 분류
- 고객을 그룹으로 나누기 → 군집화
2️⃣ 데이터 전처리
- EDA (탐색적 데이터 분석): 데이터를 시각화하고 이해하는 과정
- 결측치 처리: 평균, 중앙값 등으로 채우거나 삭제
- 스케일링 및 정규화: 모델 성능 향상을 위해 필수
- 데이터 분할: 보통 train:test = 8:2 또는 7:3
3️⃣ 모델 학습
- 학습 데이터를 기반으로 모델이 최적의 파라미터를 찾도록 학습 진행
- 에폭(epochs), 배치 크기(batch size) 설정
4️⃣ 모델 평가
- 테스트 데이터를 활용하여 예측 정확도 평가
- 평가 지표: 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-score, ROC-AUC
케라스 개발 과정 - 당뇨병 발병 유무 예측 실습
1️⃣ 문제 정의: 이진 분류 문제
- 예측 대상: 5년 이내 당뇨병 발병 여부 (Outcome: 0 = 미발병, 1 = 발병)
- 학습 데이터: 총 768건
- 목적: 8개의 건강 관련 데이터를 기반으로 당뇨병 발병 유무를 예측하는 모델 개발
2️⃣ 데이터 준비
■ 데이터셋 정보
- 출처: Kaggle - Pima Indians Diabetes Database
- 주요 변수 (8개 독립변수):
- 임신 횟수 (Pregnancies)
- 2시간 포도당 수치 (Glucose)
- 이완기 혈압 (BloodPressure)
- 피부 두겹 두께 (SkinThickness)
- 2시간 인슐린 수치 (Insulin)
- 체질량지수 (BMI)
- 당뇨병 직계 가족력 (DiabetesPedigreeFunction)
- 나이 (Age)
- 종속변수 (1개): Outcome (0 또는 1)
3️⃣ 데이터 전처리
■ 탐색적 데이터 분석 (EDA)
- 각 변수의 분포 확인
- 당뇨병 발병 여부에 따라 변수별 차이 시각화 (예: Glucose 수치가 높을수록 발병 확률 증가)
- 이상값 및 결측치 확인
■ 결측치 처리
- 일부 변수에 0 값이 포함되어 있지만, 실제로는 측정 누락으로 간주 (ex. BMI가 0은 비정상)
- 평균, 중앙값 등으로 대체하거나 삭제 (선택적)
■ 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)- 훈련셋 : 테스트셋 = 80 : 20
- stratify=y로 클래스 비율 유지

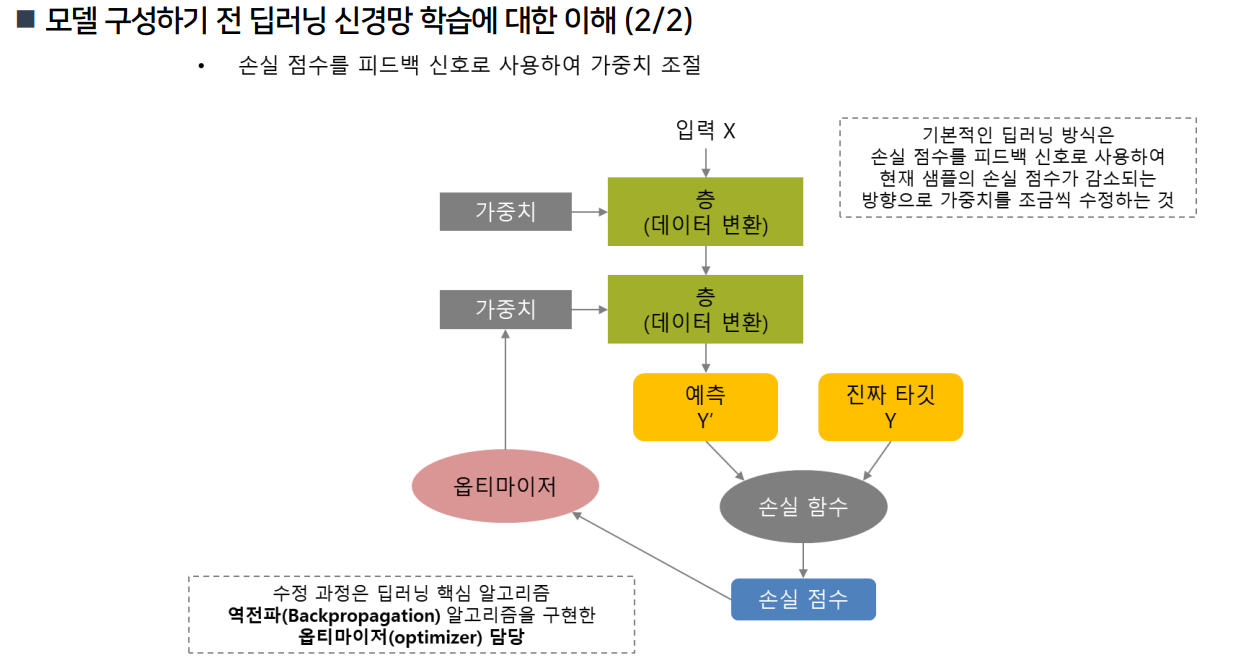
4️⃣ 모델 구성 (Keras)
■ 모델 아키텍처
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, input_shape=(8,), activation='relu')) # 입력층
model.add(Dense(32, activation='relu')) # 은닉층
model.add(Dense(1, activation='sigmoid')) # 출력층 (이진 분류)- 입력층: 8개의 feature → input_shape=(8,)
- 은닉층: Dense 64, 32 유닛 구성, ReLU 활성화 함수
- 출력층: sigmoid → 확률 값(0~1)을 출력 → 0.5 이상이면 당뇨병 판정
5️⃣ 모델 설정 (컴파일)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])- 손실 함수: binary_crossentropy (이진 분류 문제에 적합)
- 옵티마이저: adam (빠르고 효율적인 경사하강법)
- 평가지표: accuracy (정확도)
6️⃣ 모델 학습
model.fit(X_train, y_train, epochs=1500, batch_size=128)- epochs: 전체 데이터셋을 1500회 반복 학습
- batch_size: 학습할 때 한 번에 128개 데이터를 사용하여 모델 업데이트
학습 도중 손실(loss)과 정확도 추이를 통해 모델 학습 상태를 확인 가능
7️⃣ 모델 평가
loss, acc = model.evaluate(X_test, y_test)- 테스트 데이터를 이용해 모델 정확도 평가
- 추가적으로 precision, recall, f1-score, ROC-AUC 등 정밀한 지표도 분석
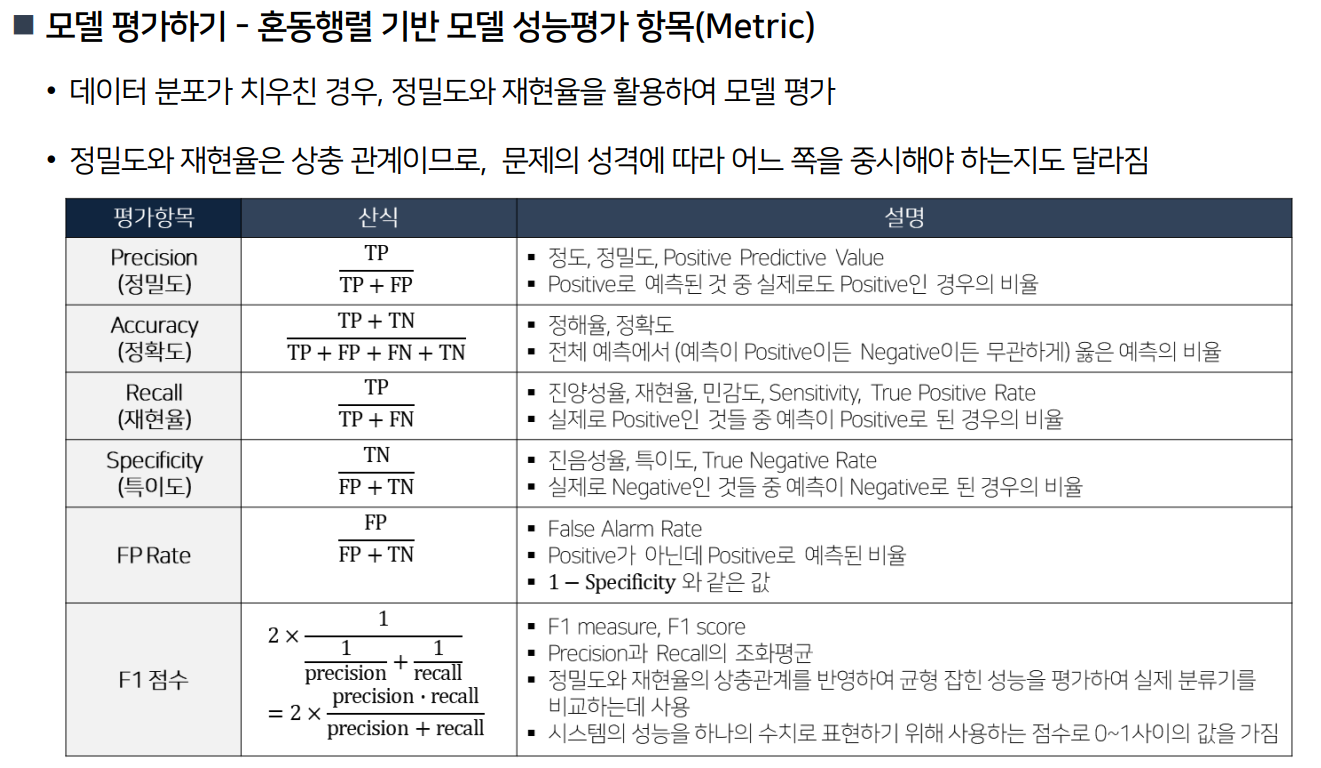
■ 혼동행렬 기반 주요 평가 지표
| 지표 | 설명 |
| Accuracy | 전체 예측 중 맞춘 비율 |
| Precision | 당뇨병이라고 예측한 것 중 실제 당뇨병인 비율 |
| Recall | 실제 당뇨병인 사람 중에서 예측이 맞은 비율 |
| F1-score | Precision과 Recall의 조화 평균 |
| ROC-AUC | 모델의 민감도와 특이도를 종합적으로 평가하는 지표 |

8️⃣ 결과 해석 및 한계
- 모델의 정확도는 중간 수준 (~70%)
- 하지만 Recall이 낮게 나오는 문제가 있음 → 실제 당뇨병 환자를 놓칠 가능성
- 따라서, 재현율을 중심으로 모델 개선 필요
- 방법: threshold 조정, 오버샘플링(SMOTE), 모델 구조 변경, 앙상블 적용 등
마무리

드디어 기다리던 인공지능 수업!!!
그동안 ‘AI’, ‘머신러닝’, ‘딥러닝’이라는 단어는 뉴스나 유튜브에서 익숙하게 접했지만, 정작 이것들이 정확히 어떤 개념인지, 어떻게 쓰이는지는 잘 몰랐는데요. 그런데 오늘 수업을 통해 그 개념들이 아주 명확해졌습니다.
AI는 인간처럼 사고하고 행동하는 기술이고, 머신러닝은 데이터를 기반으로 학습하는 방법이며, 딥러닝은 인공신경망을 활용한 고도화된 학습이라는 구조적 관계가 아직도 기억에 남군요~ 특히 ‘사람은 데이터를 주고 기계가 스스로 규칙을 찾는다’는 설명이 머신러닝의 본질을 너무 잘 표현한 문장이라 기억에 오래 남을 것 같습니다!
머신러닝 프로세스를 배우며 ‘문제 정의 → 전처리 → 학습 → 평가’라는 순서가 체계적으로 정리되어 있어 더 이해하기 편했던 것 같습니다. 평소 데이터 분석을 막연하게만 생각했는데, 수업을 통해 실제로 어떤 단계들을 거치는지, 어떤 판단을 내려야 하는지를 구체적으로 알 수 있는 시간이었다는...!
무엇보다 실습으로 진행된당뇨병 예측 모델 만들기는 AI가 어떻게 사람의 건강 문제를 예측하는 데 쓰이는지를 직접 체험해볼 수 있는 좋은 기회였습니다. 데이터셋을 불러오고, 전처리하고, 모델을 구성해서 학습과 평가까지 하는 전 과정을 따라가며, 내가 만든 모델이 어느 정도의 정확도로 ‘당뇨병 유무’를 예측한다는 것 자체가 신기했고 성취감을 느꼈습니다.
물론 결과는 완벽하지 않았습니다. 모델의 성능이 낮았고, recall 값도 충분히 높지 않았습니다.... 대충 recall 값이 0.03도 나왔다는 굉장한 사실(참고로 수가 낮을수록 안 좋습니당)... 하지만 이 또한 AI 모델이 완벽하지 않으며, 데이터를 잘 다듬고 모델을 어떻게 설계하느냐에 따라 성능이 달라진다는 점에서 굉장히 실용적인 교훈이 되었습니다. 다음에는 꼭 높은 성능이 나오도록 다시 도전해볼 예정입니다.
이번 수업을 통해 단순히 AI에 대한 이론을 배운 것이 아니라, 데이터의 흐름을 경험하면서 AI 기술이 얼마나 유용하고 실생활에 가까운지 체감할 수 있었습니다. 앞으로 더 많은 실습과 프로젝트를 통해 이 기술을 더 깊이 이해하고 활용해보고 싶습니다. 다음 수업이 벌써 기대되네요~
아 그리고 내일부터는 조원들이 교체된다는데...! 두근두근 누까될지 궁금하네요!!!
그럼 20000~
'ABC부트캠프' 카테고리의 다른 글
| [18일차] 컨볼루션 신경망 이해 및 실습 (3) | 2025.07.16 |
|---|---|
| [17일차]이진 분류 모델 실습 (타이타닉 생존자 예측) 및 인공지능 활용 신경망 실습 (0) | 2025.07.15 |
| [15일차] ESG포럼 & 세미나(2) (6) | 2025.07.13 |
| [14일차] 대전교통공사 데이터를 이용한 팀프로젝트 (1) | 2025.07.13 |
| [13일차] 멜론 TOP30 노래 정보 데이터 분석 및 시각과, 프로젝트 주제 탐색 (0) | 2025.07.13 |