데이터 분석 및 시각화 DAY6
오늘은 벌써 데이터 분석 및 시각화 6일차 입니다!
시간 진짜진짜 빨리가는 느낌이랄까요~
오늘도 뽜이팅!!! 해봅시당~

레츠키릿~
1. 멜론 TOP30 노래 정보 데이터 분석 및 시각화
1.1 패키지 설치 및 임포트, 데이터 준비하기
<패키지 설치 및 임포트>
!pip install koreanize-matplotlib
import pandas as pd
from collections import Counter
import matplotlib.pyplot as plt
import koreanize_matplotlib
import re
from wordcloud import WordCloud
import plotly.express as px
<데이터 준비하기>
df = pd.read_csv('/content/멜론 2020년 TOP30_20250709.csv')
df.head()
# 1~30위 까지의 가사에서 가장 많이 사용되는 단어는?
#특정 가수만 모아서 가수가 뭘 가장 많이 사용한는가 등을 인용
# 1) 가사컬럼만 모두 하나의 문자열로 합치기
all_lyrics = ' '.join(df['가사'])
#all_lyrics
# 2) 단어 추출
# 가사 뭉치에 단어를 추출하고, 단어의 빈도를 계산
# 정규식을 이용해서 단어를 추출 하도록 함
#\b word boundary 단어의 시작과 끝이 있는 문자로 매칭
# \w word 만 추출하도록 하고, 알파벳, 한글, 숫자까지 모두 포함
words = re.findall(r'\b\w+\b', all_lyrics.lower())
#words
# 3) 불용어 처리
stopwords = ['은','는','이','가','으로','에','그','a','the','i']
def remove_stopwords(words):
return [word for word in words if word not in stopwords]
words = remove_stopwords(words)
words
이제 크롤링 하는 법도 배웠으니 원하는 데이터를 만들어서 가져올 수 있겠죠?
저는 받는 csv파일을 바탕으로 했지만 다른 분들은 한 번 크롤링 작업을 통해 저장해서 해보시구리~
1.2 단어의 빈도표 만들기
# 단어의 빈도가 가장 높은 상위 20개의 단어와 수를 추출
word_freq = Counter(words)
#word_freq.most_common(20) #튜플형대로 지원하는 이유는 key값을 변경하지 않게 하기 위함
top_words = [word for word, freq in word_freq.most_common(10)]
top_freqs = [freq for word, freq in word_freq.most_common(10)]
# 막대 그래프로 빈도 차트 그리기
plt.figure(figsize=(10,6))
plt.bar(top_words, top_freqs)
plt.xlabel('단어')
plt.ylabel('빈도')
plt.title('2020년 TOP30 차트 가사 단어 빈도 수 TOP10')
plt.show()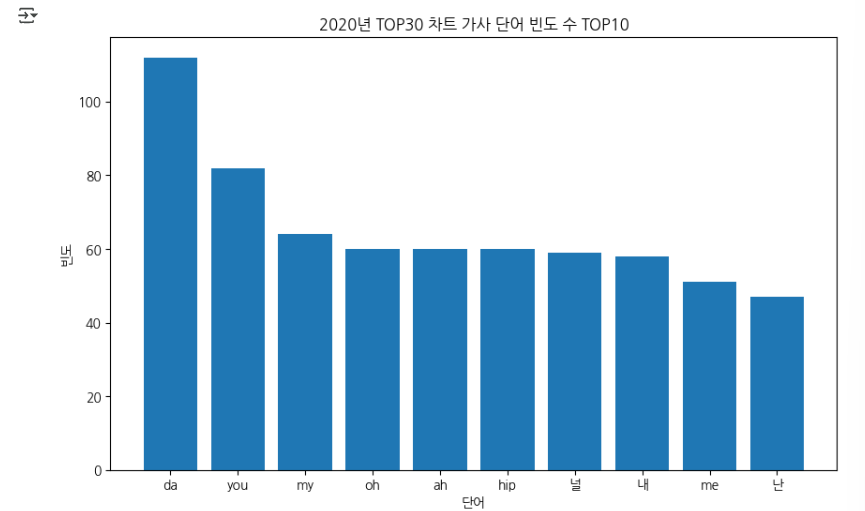
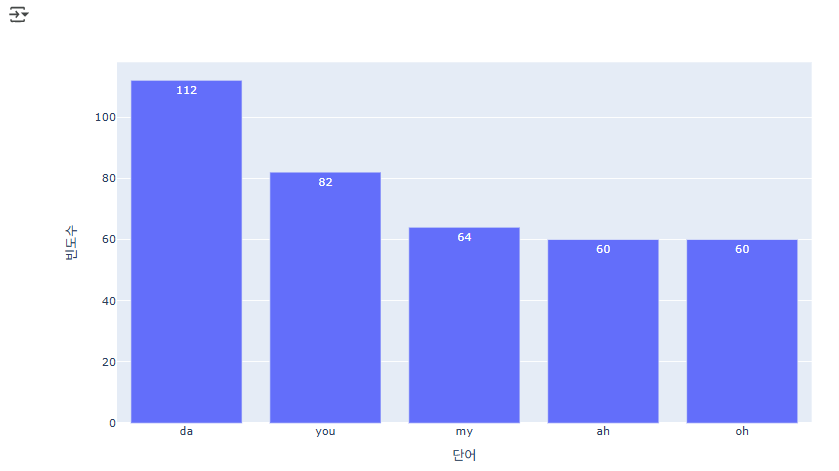
# 데이터프레임으로 만들어서 시각화
word_df = pd.DataFrame.from_dict(word_freq, orient='index').reset_index()
word_df.columns = ['단어', '빈도수']
word_df = word_df.sort_values('빈도수', ascending=False)
px.bar(word_df.head(), x='단어', y='빈도수', text_auto=True)
2. 프로젝트 주제 탐색
블로그에 써놓은 적이 없어 몰랐겠지만 사실 데이터 분석 및 시각화 파트를 배우기 시작하고 팀프로젝트를 무려 4번이나 했다는 실,,,!!!! 개인 프로젝트도 1번 하긴 했었는데 엄청 간단하고 쉬운 것들이었습니다! 하지만 오늘 오후부터는 더 깊게 하는(?) 프로젝트가 시작이 된다는,,,훙냥,,,
대전교통공사의 데이터를 이용해 문제를 해결하는 것이었는데 주제를 주시긴 했지만, 우리 최강 2조는 따로 주제를 고뇌하고 또 고뇌해서 정했답니다~ 어떤 주제인지는 비밀ㅋ

진짜 엄청난 규모의 잡초들 사이에서 꽃을 찾은 느낌이었다능,,내일 본격적으로 시작한다고 했지만
어느정도 틀을 잡고싶어 수업이 끝나고 남아 팀원들 모두 머리를 싸매고 간 슬픈 사실(흐잉)..그럼 내일도 프로젝트를 위해 화이팅!!!
'ABC부트캠프' 카테고리의 다른 글
| [15일차] ESG포럼 & 세미나(2) (6) | 2025.07.13 |
|---|---|
| [14일차] 대전교통공사 데이터를 이용한 팀프로젝트 (1) | 2025.07.13 |
| [12일차] 유튜브 댓글 수집 및 시각화 (4) | 2025.07.13 |
| [11일차] 네이버 기사 수집 및 시각화 (3) | 2025.07.07 |
| [10일차] ESG포럼 & 세미나(1) (6) | 2025.07.06 |