<목차>
- 데이터 준비하기
- 사망 교통사고 데이터 전처리
- 2021년 사망 교통사고 데이터 분석 및 시각화
- 대전광역시 사망 교통사고 데이터 분석 및 시각화
- 지도를 활용한 사망 교통사고 현황 분석
- 마무리
교통사고 데이터 분석 및 지도 시각화
데이터 분석 및 시각화 2DAY
오늘은 데이터 분석 및 시각화를 배운지 2일차!
어렵긴 하지만..! 열심히 해봐야죠!!! 오늘도 뽜이팅 🔥

오늘 배울 배용은 교통사고 데이터 분석 및 지도 시각화입니다!
레츠 GOGO!!!
데이터 준비하기
✨데이터를 준비하실 때 꿀팁을 드리자면 경도와 위도가 있는 데이터 셋으로 찾으시면 좋습니다!
왜냐하면 시각화 할 수가 있거등요~
활용한 데이터 파일입니다!
<패키지 설치 및 임포트>
!pip install koreanize-matplotlib
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import koreanize_matplotlib
import folium
import warnings
warnings.filterwarnings('ignore')전의 내용과 동일하게 패키지 설치와 임포트를 해줍니다.
오늘은 임포트 해주는게 엄청 많네요!
<데이터 불러오기>
df = pd.read_csv('/content/도로교통공단_사망 교통사고 정보_20211231.csv', encoding = 'EUC-KR')<데이터 확인하기>
항상 데이터를 불러오고 확인하는 습관 들이기!
내용이 다를 수도 있으므로 이런 습관 들이는게 중요합니다!!!
df.info()

사망 교통사고 데이터 전처리
<원본 데이터 복사하기>
accident_df = df.copy()
accident_df.head()

여기서 원본데이터를 왜 복사하는지 궁금한 분들은 위한 설명!
: 복사본을 만들어두면 전처리·컬럼 삭제·결측치 처리 등 실험적인 작업을 마음껏 해도 원본 데이터는 안전하게 보존되기 때문에 .copy()로 복사본을 만들어 사용하는 것이 안전하답니다~

<발생년월일시 컬럼에서 시간 파생 파생 컬럼 만들기>
여기서 object 타입은 단순 문자열이므로 날짜·시간 연산이 불가능합니다.
때문에 문자열(object) → datetime64 변환해줘야 합니다.
# 발생년월일시 object Dtype -> datetime Dtype 변경
# YYYY-MM-DD H:M:S
# 2000년도 전에는 YY가 아닌 yy를 사용
accident_df['발생년월일시'] = pd.to_datetime(accident_df['발생년월일시'],
format='%Y-%m-%d %H:%M',
errors='raise')
accident_df.info()# 발생년월일시 -> 발생년월일, 발생월, 발생시간
accident_df['발생년월일'] = accident_df['발생년월일시'].dt.date
accident_df['발생월'] = accident_df['발생년월일시'].dt.month
accident_df['발생시간'] = accident_df['발생년월일시'].dt.hour
- 문자열(object)로 저장된 ‘발생년월일시’를 pd.to_datetime()으로 datetime64 타입으로 변환해 날짜·시간 연산과 시계열 기능을 사용할 수 있게 합니다. 그리고 errors='raise' 옵션으로 잘못된 포맷이 있으면 즉시 알려줍니다.
- .dt 접근자를 이용해
- .dt.date → 연-월-일 (date 타입)
- .dt.month → 월 (int)
- .dt.hour → 시간(시) (int)
를 각각 새 컬럼으로 분리 생성합니다.
<전처리한 데이터 저장하기>
여기서 index=False 지정을 안할시 앞에 unnamed가 발생하기 때문에 처리를 해줘야 합니다.
나머지는 전에 배웠던 내용과 동일합니다.
accident_df.to_csv('2021년 사망 교통사고 전처리_20250702.csv',
encoding='utf-8-sig', index=False)2021년 사망 교통사고 데이터 분석 및 시각화
<전처리한 데이터 불러오기>
df1 = pd.read_csv('/content/2021년 사망 교통사고 전처리_20250702.csv')
df1
<날짜별/시간대별 교통사고 현황 분석>
날짜별·시간별 사망사고를 버블 크기와 색상으로 표현해, 언제·어디서 사망사고가 집중되는지 시각적으로 분석할 수 있습니다.
fig = px.scatter(
accident_df,
x='발생년월일',
y='발생시간',
size='사망자수',
color='발생지시도'
)
fig.show()
- px.scatter(...) 로 버블 차트를 생성합니다.
- x='발생년월일' : x축에 사고가 발생한 날짜를 표시합니다.
- y='발생시간' : y축에 사고가 발생한 시간(시 단위) 를 표시합니다.
- size='사망자수' : 각 점의 크기를 사망자 수에 비례시켜, 피해 규모를 직관적으로 보여줍니다.
- color='발생지시도' : 점의 색상을 발생 지역(시·도)별로 구분해, 지역 간 분포 차이를 한눈에 파악할 수 있습니다.
- fig.show() : 완성된 차트를 화면에 출력합니다.

<시간대별 사망 교통사고 현황 분석>
차트를 통해 하루 중 어떤 시간대에 사망사고가 가장 많은지 한눈에 파악할 수 있어, 사고 예방 대책 마련에 유용합니다.
# x축 시간, y축 사망자 수
fig = px.bar(accident_df, x='발생시간', y='사망자수')
fig.show()
- px.bar(...) : Plotly Express의 막대 차트를 생성합니다.
- x='발생시간' : x축에 사고 발생 시간(시 단위) 데이터를 배치해, 어느 시간대에 사고가 집중되는지 보여줍니다.
- y='사망자수' : y축에 사망자 수를 지정해, 각 시간대별로 얼마나 많은 사람이 목숨을 잃었는지 시각화합니다.
- fig.show() : 완성된 막대 차트를 화면에 출력합니다.
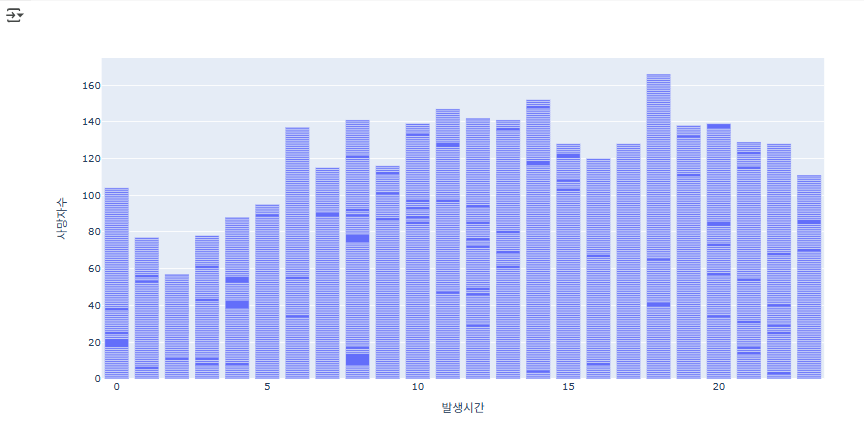
수직 막대 차트 외에도 수평 막대 차트로도 변경이 가능합니다.
시간대별 사망자 수 분포를 보는 것은 수평 막대 차트가 더 적절해 보이기 때문에 바꿔주겠습니다.
수평 막대 차트를 통해 시간대별 사망자 수 분포를 한눈에 비교할 수 있습니다.
# x축 사망자 수, y축 발생시간
fig = px.bar(accident_df, x='사망자수', y='발생시간', orientation='h')
fig.show()
훨씬 비교하기 수훨해 지지 않았나요? orientation='h'를 통해 바꾸는 작업이 가능하니 기억하는 것이 좋겠죠?!
<시도별 교통사고 사망자 현황>
.unique()로 ‘발생지시도’ 컬럼에 기록된 모든 지역명을 중복 없이 확인해, 데이터에 포함된 시·도 범주를 한눈에 파악합니다.
accident_df['발생지시도'].unique()
사고 데이터에 포함된 시·도 이름을 중복 없이 뽑아 알파벳·한글 순서대로 정리하여, 이후 분석이나 시각화 시 일관된 순서로 활용할 수 있도록 준비합니다.
#시도별로 정리가 안되있음 때문에 정리필수
#안그럼 심사위원들에게 꼬투리 잡힘
location_list = accident_df["발생지시도"].unique()
location_list.sort()
location_list.sort()를 사용해 추출된 리스트를 오름차순(알파벳/한글 순서)으로 정렬합니다.

시·도별 사망자 수를 수평 막대 차트로 시각화하며, 막대 위에 숫자를 표시하고, 지정한 순서대로 시·도를 정렬해 보여줍니다.
fig = px.histogram(accident_df, x='사망자수',
y='발생지시도',
orientation='h',
text_auto=True, category_orders={'발생지시도':location_list})
fig.show()
- px.histogram(...) : 사고 데이터에서 사망자 수를 카운트해 막대 차트 형태로 그립니다.
- x='사망자수' : 막대의 길이로 사용될 값을 지정합니다.
- y='발생지시도' : 각 수평 막대가 대응할 카테고리(시·도) 를 설정합니다.
- orientation='h' : 막대를 수평 방향으로 그리도록 지정합니다.
- text_auto=True : 각 막대 위에 값(사망자 수) 레이블을 자동으로 표시합니다.
- category_orders={'발생지시도': location_list} : y축 카테고리(시·도)를 미리 정의한 location_list 순서대로 정렬해 일관된 순서를 유지합니다.

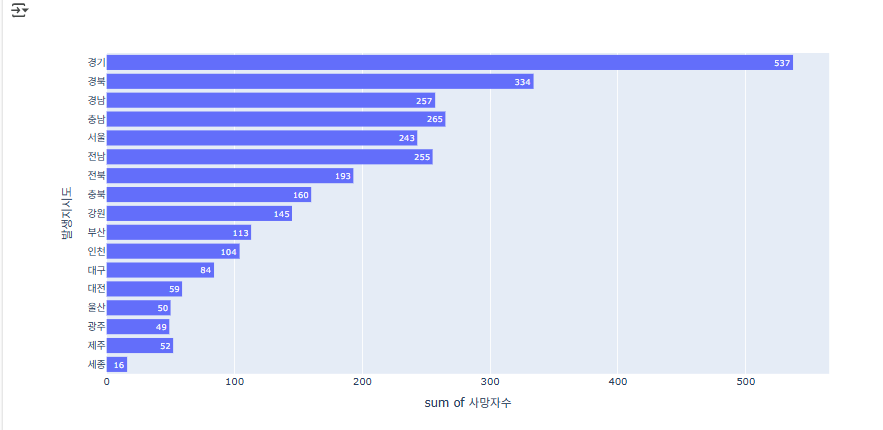
시·도별 사망사고 건수를 내림차순으로 정렬해, 사망사고가 가장 많이 발생한 지역부터 차례로 보여줍니다.
fig = px.histogram(
accident_df,
x='사망자수',
y='발생지시도',
orientation='h',
text_auto=True,
category_orders={
'발생지시도': accident_df['발생지시도']
.value_counts()
.index
}
)
fig.show()
- px.histogram(...)로 시·도별 총 사망자 수를 수평 막대 차트로 그립니다.
- text_auto=True는 각 막대 위에 사망자 수 레이블을 자동 표시합니다.
- category_orders에 value_counts().index를 넣어 발생지시도 카테고리를 내림차순(사망자 수가 많은 순) 으로 정렬한 뒤, 가장 사고가 많은 시·도가 위로 오도록 시각화 순서를 설정합니다.
시·도별 사고 발생 건수를 내림차순으로 정렬한 뒤, 그 순서대로 정리된 시·도 이름 리스트를 얻습니다.
accident_df['발생지시도'].value_counts().index<요일별 사망 교통사고 현황 분석>
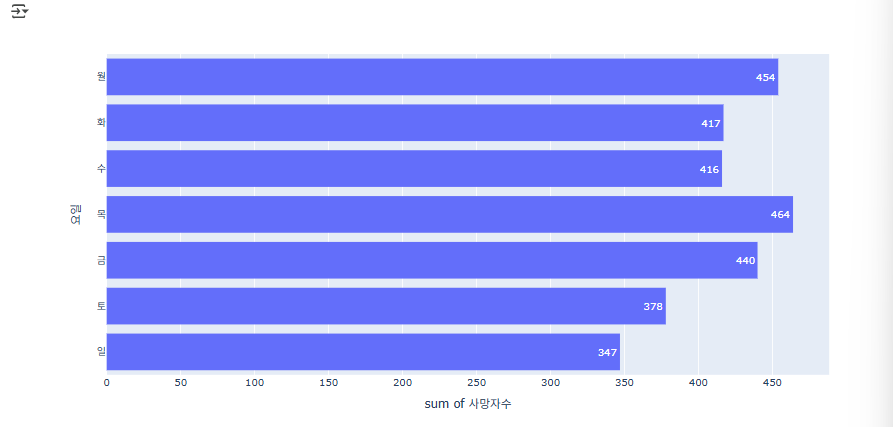
요일별 사망사고 건수를 수평 막대 차트로 시각화하며, day_list 순서대로 요일을 정렬해 어떤 요일(이 경우 목요일)에 사망사고가 가장 많은지 한눈에 보여줍니다.
# 사망 교통사고가 가장 많이 발생한 요일 -> 목요일
fig = px.histogram(accident_df, x='사망자수', y='요일', orientation='h',
text_auto=True, category_orders={'요일': day_list})
fig.show()하지만 이 경우, 요일이 차례대로 나열되는 것이 아닌 무작위로 나열되기 때문에 예쁘게 정리하기 위해 리스트를 만들 예정!
day_list = ['월','화','수','목','금','토','일']이렇게 리스트를 만들어 순서대로 요일을 적어 넣게되면 아래와 같이 요일이 순서대로 정렬되어 나타납니다.
<사고 유형별 사망 교통사고 현황 분석>
이번에는 ‘사고유형’별로 얼마나 많은 사고가 발생했는지 빈도 순으로 확인해보도록 하겠습니다!
accident_df['사고유형'].value_counts()
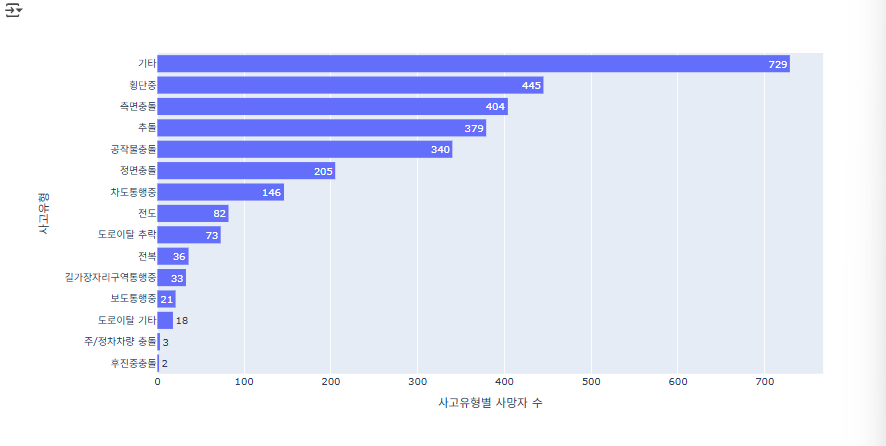
사고 유형별 사망사고 건수를 내림차순으로 보여줌으로써 ‘기타’, ‘횡단중’ 등 가장 많이 발생한 유형을 한눈에 파악할 수 있습니다.
# 사망 교통사고가 가장 많이 발생한 사고유형 -> 기타, 횡단중
fig = px.histogram(accident_df, x='사망자수', y='사고유형', orientation='h',
text_auto=True, category_orders={'사고유형': accident_df['사고유형'].value_counts().index})
fig.show()
- px.histogram(...) : ‘사고유형’별 사망자 수를 수평 막대 차트로 시각화합니다.
- x='사망자수' : 막대 길이가 그 유형에서 발생한 총 사망자 수를 나타냅니다.
- y='사고유형' : 각 수평 막대가 대응할 사고 유형(예: 기타, 횡단중 등)을 설정합니다.
- orientation='h' : 막대를 가로 방향으로 그려, 긴 이름도 읽기 쉽게 배치합니다.
- text_auto=True : 각 막대 위에 사망자 수 레이블을 자동으로 표시합니다.
- category_orders={'사고유형': …} : value_counts().index 순서대로 사고 유형을 내림차순 정렬해, 사망사고가 많은 유형부터 위에 오도록 정리합니다.

여기서 잠깐? 뭔가 수상한 점이 보이시지 않나요?!

밑에 sum of 사망자 수 라고 적혀져 있다는 것!!!
바꿔줘야 겠죠?
fig.update_xaxes(title_text='사고유형별 사망자 수')위의 코드를 통해 제목을 바꿔줍니다.
편-안
사고유형뿐만 아닌 다른유형을 넣어서도 분석이 가능하니!
바꿔보는 연습하는 것도 좋을 것 같아요ㅎㅎ
대전광역시 사망 교통사고 데이터 분석 및 시각화
이제 대전광역시의 사망 교통사고 데이터 분석 및 시각화를 해보겠습니다!
다른 지역도 가능하니 원하는 지역으로 해보는 것을 추천!!!
<대전 데이터 추출>
#쌍따옴표로를 겉으로 작은따옴표를 안으로 해서 구별하게 사용
dj_df = accident_df.query("발생지시도 == '대전'")
dj_df.info()
.query()로 ‘발생지시도’가 대전인 데이터만 추출하고, info()로 구조를 빠르게 확인합니다.

<발생시간별 사망 교통사고 현황 분석>
# 발생시간별 사망 교통사고 전국 -> 18시, 대전 -> 17시
fig = px.bar(dj_df, x='사망자수', y='발생시간', orientation='h')
fig.show()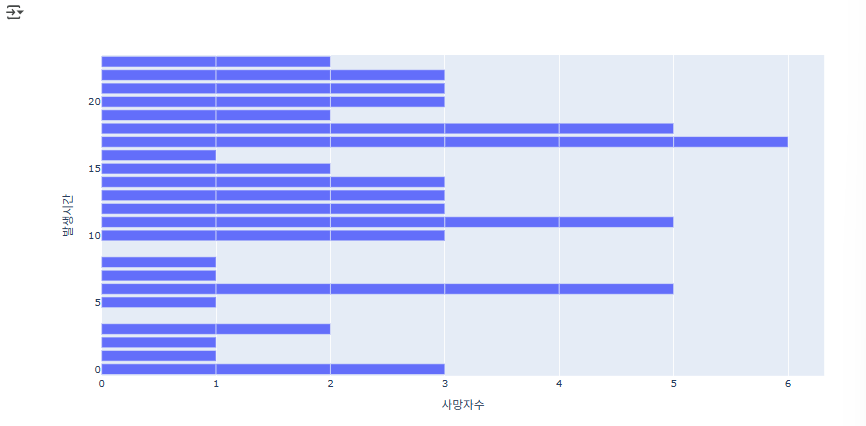
발생시간별뿐만 아닌 컬럼을 바꾸면 다양한 사망 교통사고 현황 분석도 가능하답니다!
월별, 지역구별 등등 여러가지 분석이 가능하니 한 번 해보시는 것을 추천!!!
지도를 활용해서 사망 교통사고 현황 분석
<지도 준비하기>
대전광역시 중심(위도 36.3504, 경도 127.3845)으로 초기화된 인터랙티브 지도를 생성해 화면에 표시합니다.
map = folium.Map(location=[ 36.3504119, 127.3845475])#위도,경도
map
- folium.Map(...) : Leaflet 기반의 인터랙티브 지도 객체를 생성합니다.
- location=[36.3504119, 127.3845475] : 지도의 중심 좌표를 위도, 경도 순으로 지정합니다.
- zoom_start=10 : 확대 정도를 지정하는 매개변수로, 옵션을 주지 않으면 보통 10 레벨로 설정됩니다.
- map : 노트북 환경에서 실행하면 지도 인터페이스가 화면에 렌더링됩니다.

<대전광역시 사망 교통사고 위치 지도 시각화>
소수점 연산과 외부 함수 호출에서 float 타입을 필요로 하기 때문에, 반지름 계산의 정밀도 보장과 오류 방지를 위해 미리 실수형으로 변환합니다.
# 사망자수와 부상자수를 실수형으로 변환
dj_df = dj_df.astype({'사망자수': 'float', '부상자수': 'float'})
dj_df.info()
- CircleMarker 반지름 계산
- 반지름 = (사망자수 + 부상자수) × π(3.14)
- π를 곱하면 대부분 소수점 이하 값이 나오므로, 실수형이 필요합니다.
- folium 요구사항
- CircleMarker의 radius 파라미터는 float 타입을 기대해 오류를 방지합니다

대전에서 발생한 사고 데이터를 기반으로, 피해 규모에 따라 크기가 다른 빨간원 마커를 지도 위에 표시하고 클릭 시 사고 유형을 팝업으로 보여줘, 지리적 분포와 사고 특성을 동시에 시각화
# 1) 기본 지도 준비
map = folium.Map(
location=[36.3504119, 127.3845475], # 대전광역시 중앙 좌표
zoom_start=13 # 초기 확대 레벨
)
# 2) CircleMarker 지도 표출
for n in dj_df.index:
cnt = dj_df['사망자수'][n] + dj_df['부상자수'][n] # ① 마커 크기 계산
lat = dj_df['위도'][n] # ② 위도 추출
lng = dj_df['경도'][n] # ③ 경도 추출
folium.CircleMarker(
location=[lat, lng], # ④ 마커 위치
radius=cnt * 10, # ⑤ 크기 배율(가시성 향상)
popup=dj_df['사고유형'][n], # ⑥ 클릭 시 사고 유형 표시
color='red', # ⑦ 외곽선 색
fill_color='red' # ⑧ 내부 채움 색
).add_to(map)
map # ⑨ 인터랙티브 지도 렌더링
- ① 마커 크기 계산
사망자수 + 부상자수를 합산해, 사고 규모(피해자 수)에 비례하는 크기를 정합니다. - ②·③ 위도·경도 추출
각 사고 데이터의 위치 정보를 가져와 마커가 정확한 지점에 찍히도록 합니다. - ④ 위치 지정
location 파라미터에 [lat, lng]를 전달해 마커를 해당 좌표에 배치합니다. - ⑤ 크기 배율
실제 값만으로는 너무 작거나 커 보일 수 있어 ×10 배율을 적용해 시각적으로 구분하기 좋게 조정합니다. - ⑥ 팝업 설정
마커를 클릭하면 사고유형 텍스트가 표시되어 사고 상황을 바로 확인할 수 있습니다. - ⑦·⑧ 스타일 지정
빨간색 테두리와 채움색으로 사고 지점을 강조합니다. - ⑨ 지도 렌더링
노트북 환경에서 map을 호출하면 인터랙티브 지도가 화면에 나타납니다.

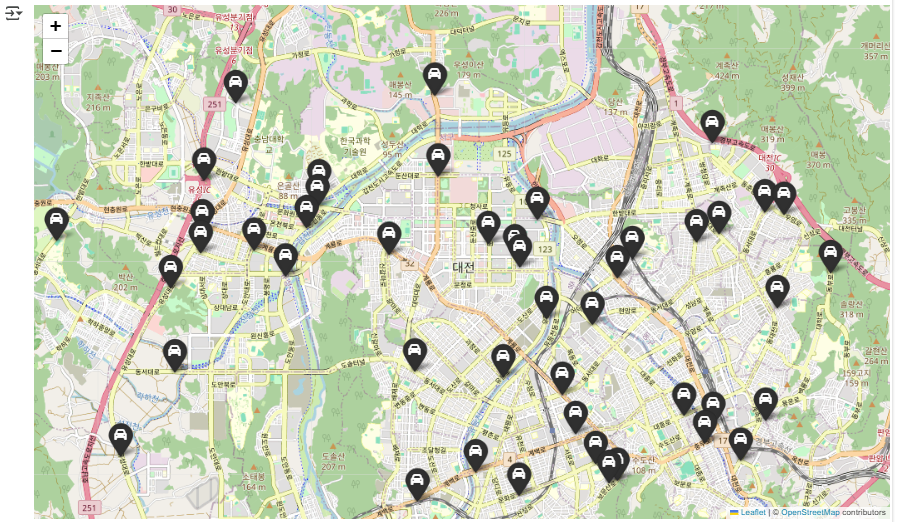
대전 지역 사고 데이터를 폴리움 기본 마커와 FontAwesome 자동차 아이콘으로 지도에 표시하고, 클릭 시 사고 유형을 팝업으로 시각화
# 1) 기본 지도 준비
map = folium.Map(
location=[36.3504119, 127.3845475],
zoom_start=13
)
# 2) Marker 지도 표출
for n in dj_df.index:
cnt = dj_df['사망자수'][n] + dj_df['부상자수'][n] # (계산은 했지만 Marker에서는 사용되지 않음)
lat = dj_df['위도'][n]
lng = dj_df['경도'][n]
folium.Marker(
location=[lat, lng],
popup=dj_df['사고유형'][n],
icon=folium.Icon(color='black', icon='fa-car', prefix='fa')
).add_to(map)
map
- folium.Map(...)로 대전의 위도·경도와 시작 줌 레벨을 지정해 기본 지도를 생성합니다.
- for n in dj_df.index:를 통해 대전 사고 데이터(dj_df)의 각 행을 순회합니다.
- cnt 변수는 사망자수 + 부상자수를 계산하지만, CircleMarker 대신 Marker를 사용할 경우에는 크기 조정에 활용되지 않습니다.
- 각 행에서 위도와 경도를 추출해 location에 전달해 마커 위치를 지정합니다.
- popup에 사고 유형을 설정해 마커를 클릭했을 때 사고 종류를 보여주고, icon=folium.Icon(...)으로 검은색 자동차 모양 FontAwesome 아이콘을 사용해 시각적으로 강조합니다.
- 마지막에 map을 호출하면 노트북 환경에서 인터랙티브 지도가 렌더링됩니다.
아이콘은 https://fontawesome.com/v4/icons/ 에서 다양하게 확인이 가능하니 참고해주세요~
이렇게 시각화한 파일을 저장하면 끝이 난답니다!
<대전광역시 사망교통사고 지도 시각화 저장(html)>
map.save('2021년 대전광역시 사망교통사고 현황 지도.html')마무리
이번 강의를 따라오면서, 교통사고 데이터를 다루는 흐름이 훨씬 더 입체적으로 느꼈던 것 같습니다. 원본 데이터를 복사해 안전망을 만든 뒤, 날짜·시간 정보를 datetime으로 바꿔 시계열 분석의 문을 연 순간부터 “아, 이래서 데이터 타입이 중요한 거구나” 하고 감탄이 절로 나왔습니다. 단순히 문자열로 보이던 ‘발생년월일시’가 진짜 시간 축 위에 놓이니, 버블 차트에서 언제·어디서 사망사고가 집중됐는지 한눈에 파악할 수 있었던 게 인상적이었달까요?!
시간대별 막대 차트를 수직, 수평 막대로 바꿔보며 시각화의 유연성을 체험해보니, “한 가지만 고집할 게 아니라 필요에 따라 표현 방식을 바꿔야겠다”는 생각이 들었습니다. 그리고 시·도별, 요일별, 사고유형별, 가해자법규위반별로 카테고리 순서를 직접 정리하고 차트를 그려내는 과정은, 작은 디테일 하나가 전체 메시지의 설득력을 얼마나 좌우하는지를 확실히 알게되었다는..!
대전광역시 데이터를 따로 추출해 분석하면서는, 특정 지역에 집중된 인사이트를 얻는 재미가 있었습니다. 특히 folium으로 지도를 만들고, 피해 규모에 비례해 크기가 달라지는 CircleMarker를 찍어보니 ‘데이터 위에 진짜 공간 정보가 올라간다’는 느낌이 들었습니다. Marker에 자동차 아이콘을 씌워 보기도 했는데, 이렇게 시각적 요소를 조금씩 바꿔가며 지도에 풍부함을 더할 수 있다는 점도 흥미로웠습니다.
마지막으로, 완성된 지도를 HTML로 저장해 공유할 수 있다는 사실이 강의의 마침표 같았어요. “내가 만든 분석 결과물을 배포할 수 있구나” 하는 성취감이 들었습니다. 앞으로 이 워크플로우를 기본으로 삼아, 다른 주제의 데이터에 적용해보고, 더 인터랙티브한 대시보드로 발전시켜나가고 싶다는 의욕이 솟구칩니다.
내일도 열심히 달려봅시다~화이팅!

'ABC부트캠프' 카테고리의 다른 글
| [10일차] ESG포럼 & 세미나(1) (6) | 2025.07.06 |
|---|---|
| [9일차] 텍스트 데이터 분석 및 시각화 (3) | 2025.07.06 |
| [7일차] 인구 데이터 분석 및 시각화 (3) | 2025.07.05 |
| [6일차] 간단한 데이터 집계와 데이터 처리 심화 (1) | 2025.07.02 |
| [5일차] 데이터 처리 기초(2) (0) | 2025.06.29 |